Traditional SQL stored procedures don’t exist in the noSQL Firestore database world, and it’s very common for business logic to demand this capability in growing platforms.
For example, you might need to run a daily recalculation of the interest owed on the installments of active loans. Or maybe you need to review all users and update their status according to some criteria. You could run a scheduled cloud function for this, but what if you need to iterate over 100k documents? Or 1 million? The cloud function would probably timeout or run out of memory.
A posible solution proposes separating the problem into a smaller problems, and we can achieve this with two cloud functions: an orchestrator and a calculator.
The orchestrator queries the collection in batches of n documents, and sends a PubSub message to trigger the calculator function for one document. If the size of the query is equal to n, this means that there are more documents in the collection and it sends a PubSub message to call itself again and processes the next n documents.
Orchestrator function implementation. n = 1000
export const orchestratorFunction = functions.pubsub
.topic("orchestratorFunction")
.onPublish(
(message: functions.pubsub.Message, context: functions.EventContext) => {
const QUERY_LIMIT = 1000;
const db = admin.firestore();
const publisher = new PubSub();
const collection = message.json.collection;
const calculatorFunctionTopic = message.json.calculatorFunctionTopic;
// Collection we want to query.
let query = db.collection(collection);
const startAfter = message.json.startAfter;
let size = 0;
// On the first run, startAfter will come empty.
if (startAfter) {
functions.logger.info(`Start after: ${startAfter}.`);
// If the collection has more documents than QUERY_LIMIT,
// the subsequent executions will have this value.
query = query.startAfter(startAfter);
}
return query
.limit(QUERY_LIMIT)
.get()
.then(async snap => {
size = snap.size;
functions.logger.info(`Size: ${size}. First: ${snap.docs[0].id}.`);
// Call the orchestrator function again with the start after value.
// If the size is less than the query limit, this is the last execution.
if (size === QUERY_LIMIT) {
const lastId = snap.docs[size - 1].id;
functions.logger.info(`End on: ${lastId}`);
// Calls the same orchestrator function again for the next QUERY_LIMIT documents
await publisher
.topic("orchestratorFunction")
.publishJSON({
startAfter: lastId,
collection,
calculatorFunctionTopic,
});
}
const pubSubPromises = [] as Promise<any>[];
snap.forEach(doc => {
// Calls the calculator function for each docId.
const pubSubPromise = publisher
.topic(calculatorFunctionTopic)
.publishJSON({ id: doc.id, collection });
pubSubPromises.push(pubSubPromise);
});
return Promise.all(pubSubPromises);
});
}
);The calculator function executes the business logic for one document of the collection.
Calculator function implementation
export const calculatorFunction = functions
.runWith({ maxInstances: 20 })
.pubsub.topic("calculatorFunction")
.onPublish(
(message: functions.pubsub.Message, context: functions.EventContext) => {
const id = message.json.id;
const collection = message.json.collection;
const db = admin.firestore();
// Business Logic
// Insert your business logic that updates the document
const updateData = {};
return db
.collection(collection)
.doc(id)
.update({ ...updateData, lastProcessed: new Date() });
}
);Notice this cloud function has a max instances property (line 2). This could be useful if your calculator function fetches and writes lots of data and you want to avoid overloading your database. The lower the max instance amount, the longer the entire process will take.
To make sure all documents were processed, you could query the collection on the lastProcessed field to find any documents that have an older timestamp than when the processed started.
To start the process, you could call the orchestrator function with a PubSub message to the topic orchestratorFunction and the following payload
{
"collection" : "users",
"calculatorFunctionTopic" : "calculatorFunction"
}Notice the absence of the
startAfterkey, this indicates to the orchestrator function to start from the beginning of the collection.
or set up a cloud scheduler task:
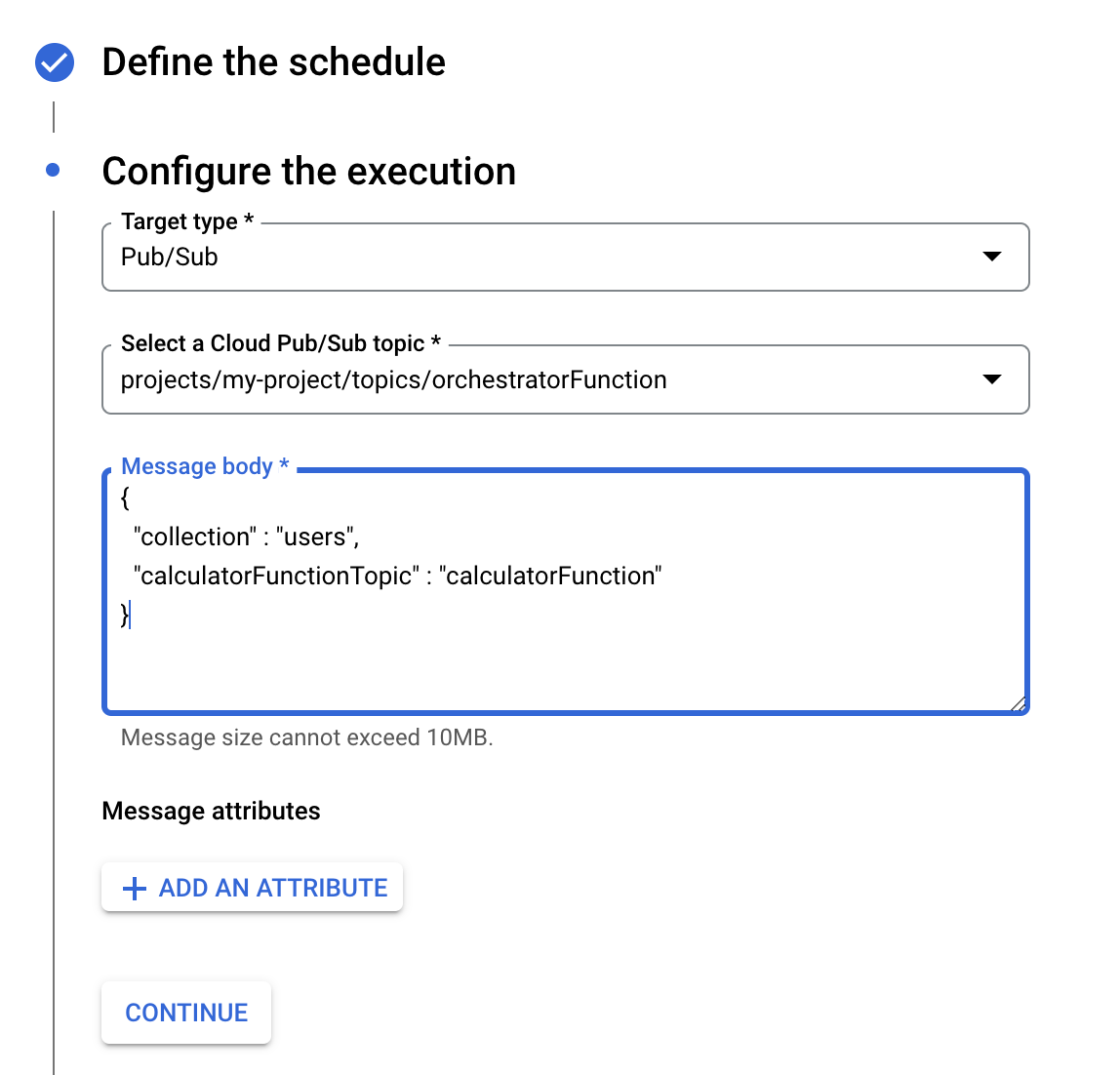 Setting up cloud scheduler task
Setting up cloud scheduler task
You can set up as many cloud scheduler tasks as you may need for your various calculator functions.